
Bert Embeddings with Huggingface Transformers
4 September, 2023
BERT, short for "Bidirectional Encoder Representations from Transformers," is your secret weapon in the world of natural language understanding. This article will show you how to leverage this powerful tool, with a little help from our friends at Hugging Face Transformers.
What Are Embeddings?
In the world of natural language processing and machine learning, embeddings are a fundamental concept. They serve as a bridge between raw data, like words or sentences, and the numerical data that machine learning models can understand.
Word Embeddings
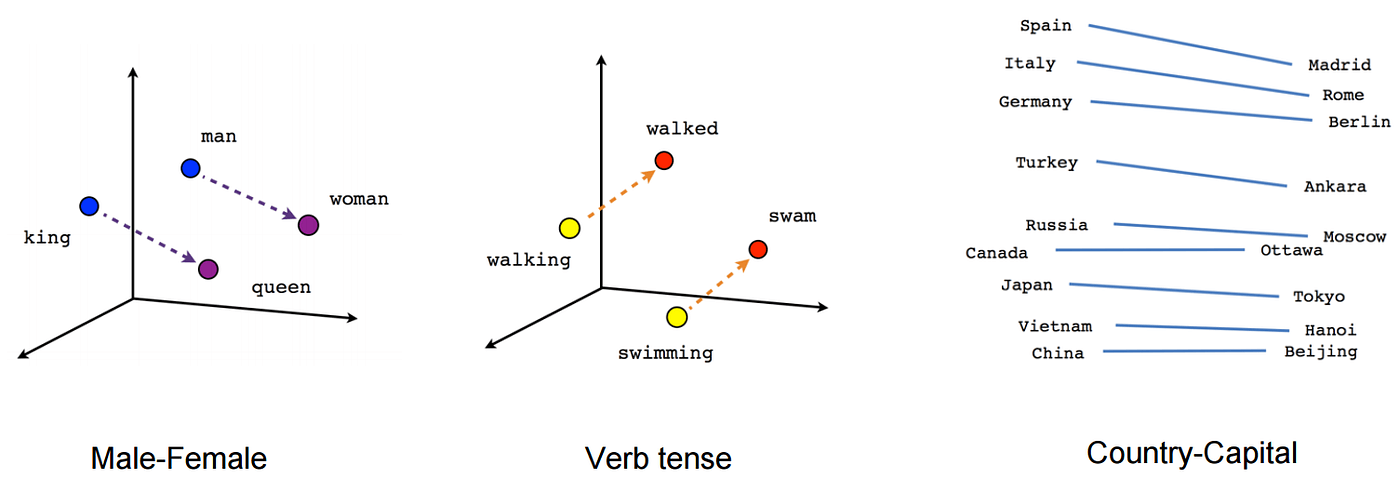
Word embeddings, in particular, are representations of words in a mathematical form. They capture the semantic meaning of words, allowing machines to understand the context and relationships between words. In essence, they transform words into vectors in a high-dimensional space, where similar words are closer to each other. For example, in a well-trained word embedding model, the vectors for "king" and "queen" would be closer together than "king" and "cat."
BERT Word Embeddings
BERT (Bidirectional Encoder Representations from Transformers) takes word embeddings to the next level. It's not just about individual words; BERT understands the context in which words appear. This contextual understanding means that the embedding of a word can change depending on its usage in a sentence.
For instance, the word "bat" can refer to a flying mammal or a piece of sports equipment. Traditional word embeddings might create the same embedding for "bat" in both contexts, while BERT would differentiate them based on the surrounding words.
Why BERT Embeddings?
BERT embeddings have become instrumental in natural language understanding because they capture the nuances of language. Here's why they are so powerful:
- Contextual Understanding: BERT comprehends words not in isolation but in the context they are used. This context-awareness is a game-changer for tasks like sentiment analysis, where the meaning of a word can change based on its context.
- Positional Awareness: BERT can handle the position of words exceptionally well. It understands where words are located in a sentence, which is crucial for understanding the structure and meaning of text.
- Versatility: BERT embeddings can be used for a wide range of language-related tasks, from classification and sentiment analysis to question-answering and translation. They serve as a versatile tool for language understanding.
Hugging Face Transformers to the Rescue
Now, handling BERT can be a bit tricky. But fear not! Hugging Face Transformers is here to save the day. It simplifies the complex code, making it easy for you to work with these language giants. It's your one-stop-shop for loading, training, and saving Transformer models of any size. Plus, it's eco-friendly, as you can reuse pre-trained models shared by researchers. 🌱
Pipelines Inside Transformers
Pipelines are your friendly neighborhood tool in the Transformers world. They're your gateway to BERT's magic. With just a few lines of code, you can use these pipelines for tasks like language understanding, sentiment analysis, feature extraction, question answering, and more. 🚀
Language Translation Made a Breeze
python
from transformers import pipeline
translator = pipeline("translation_en_to_fr")
translation = translator("What's your name?")
Want to translate English to French? No problem! With Hugging Face Transformers, it's as easy as pie. Just fire up a translation pipeline, and voilà! 🇫🇷
Zero-Shot Classification: Super Adaptable
python
from transformers import pipeline
zero_shot_classifier = pipeline("zero-shot-classification")
result = zero_shot_classifier("This is a review about a smartphone.", candidate_labels=["Gadgets", "Food", "Movies"])
Sorting text in multiple languages? Hugging Face's Zero-Shot Classification model has got your back. It adapts on the fly, even without prior category knowledge. 🚀
Sentiment Analysis Simplified
python
from transformers import pipeline
chosen_model = "distilbert-base-uncased-finetuned-sst-2-english"
distil_bert = pipeline(task="sentiment-analysis", model=chosen_model)
result = distil_bert("This movie is great!")
Creating a sentiment analysis model is a breeze with Hugging Face Transformers. Choose the right model for your task, like the "distilbert-base-uncased-finetuned-sst-2-english," and you're good to go! 📊
Question Answering Like a Pro
python
from transformers import pipeline
qa_pipeline = pipeline("question-answering")
query = "What is my place of residence?"
context_text = "I live in India."
qa_result = qa_pipeline(question=query, context=context_text)
Need answers from text? Use the question-answering pipeline. It's like having a smart tool at your fingertips. Just provide the question and context, and let it do the rest! 🧐
BERT Embeddings in Context
python
import torch
from transformers import BertTokenizer, BertModel
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained("bert-base-uncased")
custom_text = "You are welcome to utilize any text of your choice."
encoded_input = tokenizer(custom_text, return_tensors='pt')
output_embeddings = model(**encoded_input)
BERT word embeddings are where the magic happens. These embeddings understand context, adapting word representations based on their usage within sentences. Traditional embeddings can't match this finesse. 🔍